Intel is trying to capture a slice of the fast-moving deep learning, AI and neural network market and claims in its marketing materials that its Xeon Phi is better suited for this task than GPUs.
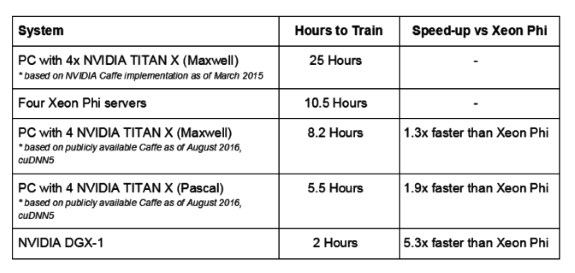
First up, Intel claims the Xeon Phi is 2.3 times faster in training than GPUs. NVIDIA refutes this claim by pointing out that Intel used Caffe AlexNet data that is 18 months old, whereas more recent data reveals four Maxwell GPUs deliver 30 percent faster training than four Xeon Phi servers, and a system with four Pascal-based Titan X GPUs and a single NVIDIA DGX-1 is over five times faster than four Xeon Phi servers.
Next is Intel's statement that its Xeon Phi offers 38 percent better scaling than GPUs across nodes, a statement NVIDIA disputes because Intel used the Oak Ridge National Laboratory’s Titan supercomputer as the basis for this comparison. This system uses four-year old Tesla K20X GPUs and an interconnect technology inherited from the prior Jaguar supercomputer. NVIDIA argues benchmarks from Baidu show that their speech training workload scales almost linearly up to 128 GPUs, thereby also refuting Intel's claim that GPUs do not scale as well as 128 Xeon Phi servers.
NVIDIA ends its rebuttal by urging Intel to keep up to date and get their facts straight:
While we can correct each of their wrong claims, we think deep learning testing against old Kepler GPUs and outdated software versions are mistakes that are easily fixed in order to keep the industry up to date.
It’s great that Intel is now working on deep learning. This is the most important computing revolution with the era of AI upon us and deep learning is too big to ignore. But they should get their facts straight.