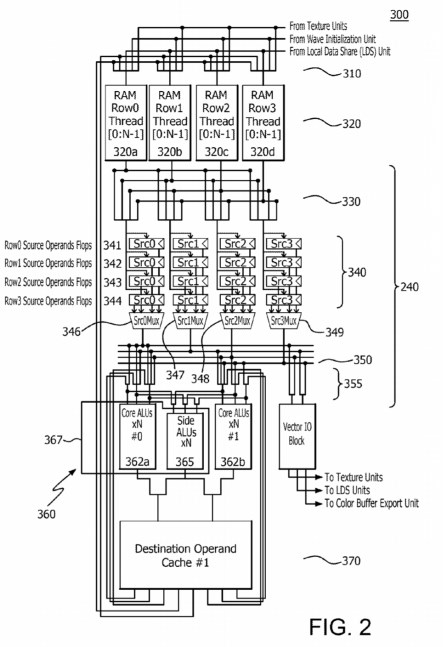
Legit Reviews writes this looks like a major change to the Compute Unit (CU) used on the current Graphics Core Next (GCN) GPU architecture. The site notes this looks a bit similar to what AMD used for its Bulldozer architecture, where two or more ALUs are grouped together. The group has a small cache, which allows results from an operation to bypass the L1 cache and pass immediately to another ALU in the group.
A super single instruction, multiple data (SIMD) computing structure and a method of executing instructions in the super-SIMD is disclosed. The super-SIMD structure is capable of executing more than one instruction from a single or multiple thread and includes a plurality of vector general purpose registers (VGPRs), a first arithmetic logic unit (ALU), the first ALU coupled to the plurality of VGPRs, a second ALU, the second ALU coupled to the plurality of VGPRs, and a destination cache (Do$) that is coupled via bypass and forwarding logic to the first ALU, the second ALU and receiving an output of the first ALU and the second ALU. The Do$ holds multiple instructions results to extend an operand by-pass network to save read and write transactions power. A compute unit (CU) and a small CU including a plurality of super-SIMDs are also disclosed.