
Monolithic GPUs are rapidly hitting the limits of what is physically possible. It's getting increasingly difficult to cram more transistors in a single die and there are limits to how big you can make a die, especially if you also want good yields. So NVIDIA is investigating the use of multi-chip modules (MCM) to pack several smaller GPUs on a single package.
Putting multiple GPUs on a single PCB has problems too so NVIDIA's researchers investigated the potential of a multi-chip package with four smaller dies connected via a fast interconnect architecture that could potentially offer terabytes per second of bandwidth.
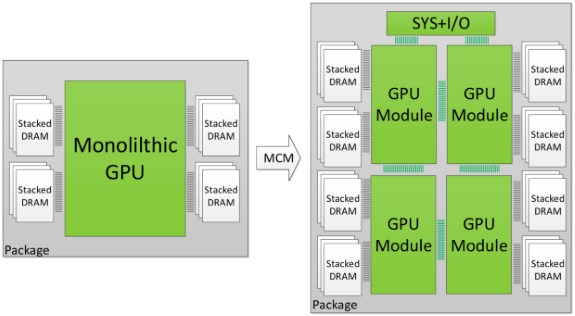
NVIDIA has a GPU simulator so the company can test the properties of these virtual chips. The team modeled the hypothetical GPUs to be similar to, but extrapolated in size compared to the Pascal architecture.
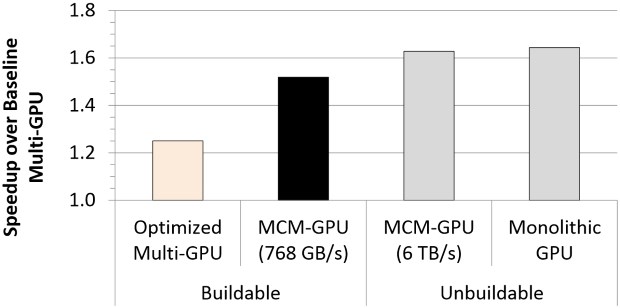
The team found MCMs are a good way to extend GPU performance scaling and that they are energy and cost efficient. The primary bottleneck appears to be inter-GPU bandwidth but the team concludes that with optimizations, a buildable MCM GPU with a total of 256 streaming multiprocessors (SM) offers 45.5 percent higher performance than the largest possible monolithic GPU with 128 SMs.
A video card with the MCM GPU performs 26.8 percent better than a similar multi-GPU card, and is just 10 percent slower than a similar monolithic GPU that cannot be build with current technology.
We show that with these optimizations, a 256 SMs MCM-GPU achieves 45.5% speedup over the largest possible monolithic GPU with 128 SMs. Furthermore, it performs 26.8% better than an equally equipped discrete multi-GPU, and its performance is within 10% of that of a hypothetical monolithic GPU that cannot be built based on today’s technology roadmap.
Rumor has it that AMD may be pursuing similar ideas with its future Navi GPU.
Via: TechReport